When most SaaS teams talk about adding AI to their product, they think of a
sidebar assistant that drafts text or a modal that pastes content into the
editor. But a true AI copilot doesn’t live outside the editor—it
lives within it. It understands the document, its structure, the user’s intent
and can edit, reorganize, and reason over complex content.
That’s what we built when working with our client, Distribute, a go-to-market
platform with a collaborative document editor. Here’s what we learned while
turning a traditional editor into an AI-native workspace.
Distribute’s text editor uses a structured, schema-based document system that
supports custom layouts, tabbed sections, and user mentions. To make AI truly
useful in that context, we needed more than a content generator. The copilot had
to:
Understand the entire document structure (not just current selection)
Modify any part of it, from rewriting a paragraph to merging two tabs
Preserve strict schema validity and contextual placeholders
Respect the collaboration model — users must see, review, and accept
changes safely
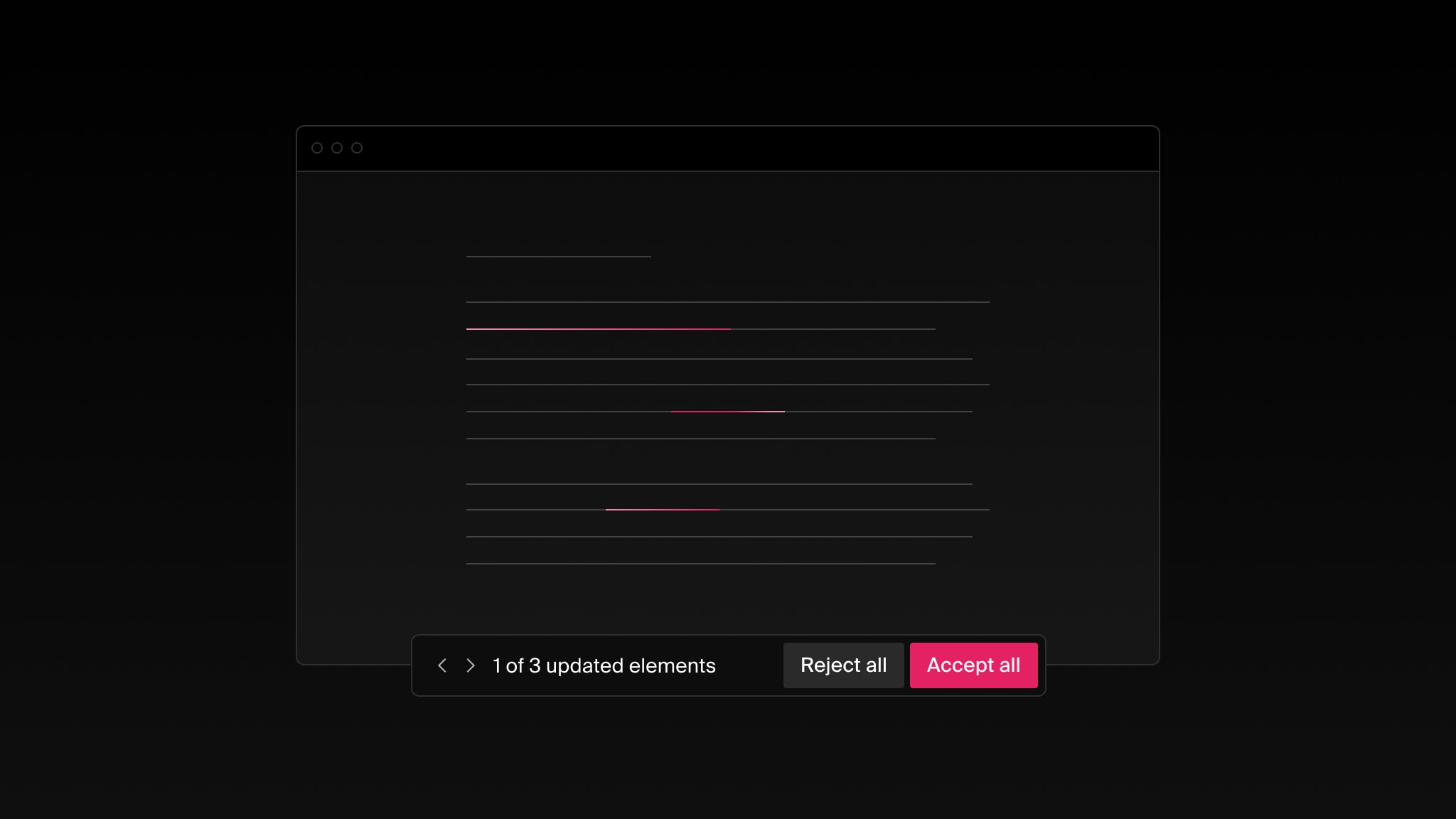
The result: a copilot that feels native to the editor, not bolted on top.
The editor with diffs, and AI chat with diffs, accept/reject dialog
Distribute’s editor runs on Tiptap, built over ProseMirror, meaning every
node and mark is validated against a schema. That’s great for consistency but
hard for AI, since large language models are much more comfortable producing
text than tree structures.
Our first idea was to ask the LLM to generate a stream of edit operations
referencing node IDs. In practice, this proved unstable—the model could easily
lose track of structure, break references, or output malformed operations.
So we inverted the problem. Instead of operations, the model outputs a complete
edited document, but written in a restricted JSX-style markup that mirrors our
schema. Alongside it, the model includes a short meta-comment explaining what it
changed and why.
We then diff this version against the user’s original document to extract
precise edits.
// System prompt for AI copilotconstSYSTEM_PROMPT=`# RESPONSE FORMATReturn JSON with two fields:{ "doc": "<complete edited document in allowed markup>", "comment": "<brief explanation of changes>"} # ALLOWED MARKUP ELEMENTS- Structure: <Doc>, <Tab id="x" name="Y">- Text: <Paragraph>, <Heading level="1-3">, <HardBreak>- Formatting: <Bold>, <Italic>, <Strike>, <Underline>- Lists: <BulletList>, <OrderedList>, <ListItem>- Special: <CustomLink href="...">, <CustomImage src="...">, <ContactCard>- NEVER modify: <ContactCard>, <CustomTaskList>, <Button>, <VideoRecord> # RULES- Return COMPLETE document, preserving all unchanged content- Keep all node attributes (ids, alignment, etc.)- Never invent new tags or attributes- Preserve all special blocks exactly as provided`; // JSX-style documentconst documentKnowledge =`<Doc> <Tab id="tab1" name="Overview"> <Paragraph>Current proposal draft...</Paragraph> </Tab></Doc>`; // Document contextconst metadataKnowledge =`{ "title": "Enterprise Sales Proposal", "userName": "John", "userCompany": "Acme Corp"}`;
“We realized that LLMs are great at rewriting but terrible at patching. Once we gave it a strict language and compared outputs ourselves, everything clicked.”
Myron MavkoFounder at Flexum
This design gave us reliability without sacrificing flexibility.
Diffing two structured documents is hard. Naive character/word diffs ignore node
boundaries and semantics; purely tree-based diffs often treat intra‑node text
edits as whole‑node replacements, obscuring the minimal change set. We needed
both views at once. We built a hybrid method we call extended-text diffing.
The idea is to flatten the document into a text-like sequence but preserve
structure as metadata. We convert every visible and invisible element into a
token—even visual blocks like images or dividers get symbolic representations.
Each token carries metadata about its original formatting and position in the
tree.
This lets us:
Run a classic text-diff algorithm (LCS-style) on the flattened form.
Reconstruct a structured document with semantic awareness.
Label every node as unchanged, added, updated, or removed.
The outcome is a perfect balance: simple diff logic, yet structure-aware
precision.
Waiting for the full model response before showing anything would make the
experience feel sluggish. Instead, we stream tokens as they arrive and
immediately generate diffs on that partial content so the user can watch the
copilot’s work unfold in realtime.
The challenge is that a streamed document is incomplete, so the temporary tail
of the diff may falsely appear to be removed text simply because those tokens
haven’t arrived yet. To keep the experience consistent, we hide that trailing
removal fragment until streaming completes, revealing the full text once the
model finishes.
This way, users see responsive, continuously updating feedback with accurate
diffs from the first second to the last.
Our AI App Builder example demos this—the trailing code is kept visible until the stream completes.
In a shared document, AI should never surprise teammates. Our rule: preview
locally, publish deliberately.
Here’s the workflow:
When a user invokes the copilot, their editor switches to a read‑only diff
view of the proposed changes.
Other collaborators continue editing as usual; their updates keep syncing and
are immediately reflected in the user’s diff view.
The user can review, chat, and iterate as needed. Accept applies the change
set and publishes it to everyone as that user’s edits; Reject discards it.
This keeps the session private without pausing collaboration or forking state.
The implementation is a custom diff renderer inside the editor—no paid editor
plugins, no special server mode. It works with any strict‑schema editor and any
real‑time layer (e.g., Liveblocks) because it’s just view state plus
deterministic apply/revert.
// Copilot UI ComponentfunctionAICopilotPreview({ diffDoc, onAccept, onReject }){return(<divclassName="copilot-preview">{/* Read-only editor showing diff */} <TiptapEditor content={diffDoc} editable={false} extensions={[// Render insertions in green, deletions in red with strikethroughDiffMark.configure({HTMLAttributes:{"data-insert":{class:"bg-green-100 text-green-900"},"data-delete":{class:"bg-red-100 text-red-900 line-through"},"data-update":{class:"bg-blue-100 text-blue-900"},},}),]} /> {/* Controls */}<divclassName="controls"><buttononClick={()=>{onAccept();}}> ✓ Accept Changes</button> <buttononClick={()=>{// Discard suggestions, return to originalonReject();}}> ✗ Reject</button></div></div>);}
This handles the diff preview outside of the AI chat, but we need to build the
AI chat itself, with its own accept/reject dialog.
Most AI chat libraries are built on HTTP streaming, which is prone to breaking
due to network issues, timeouts, and other factors. Additionally, it’s difficult
to handle front-end tool calls, confirmation flows, and realtime feedback with
HTTP streaming, which is why
we recommend using WebSockets instead of HTTP for AI chats.
The ready-made Liveblocks
AiChat component handles all
this, rendering a realtime chat interface, and you can add the current document
state to the chat as
knowledge,
so it understands the starting point before it makes changes.
import{AiChat,AiTool}from"@liveblocks/react-ui";import{RegisterAiKnowledge}from"@liveblocks/react";import{ useEditor }from"@tiptap/react";import{EditDocumentTool}from"./EditDocumentTool"; functionChat({ chatId, metadata }){const editor =useEditor(); return(<>{/* The Liveblocks AI chat component*/}<AiChatchatId={chatId}/> {/* Giving the AI chat the current document */}<RegisterAiKnowledgedescription="The current document"value={editor.getJSON()}/> {/* Giving the AI chat the document's metadata */}<RegisterAiKnowledgedescription="The current metadata"value={metadata}/> {/* See below */}<EditDocumentTool/></>);}
Alongside this you need a
human-in-the-loop tool
that allows AI to edit and stream in the changes in realtime, with a
confirmation flow, so that the user can accept or reject the changes.
import{AiTool}from"@liveblocks/react-ui";import{RegisterAiTool}from"@liveblocks/react";import{ defineAiTool }from"@liveblocks/client";import{ useEditor }from"@tiptap/react";import{ applyDiff, generateDiff,DiffPreview}from"src/utils/diff"; functionEditDocumentTool(){const editor =useEditor(); // A tool that allows AI to edit the documentreturn(<RegisterAiTool name="edit-document" tool={defineAiTool()({ description:"Edit a document", parameters:{ type:"object", properties:{ doc:{ type:"string"}, comment:{ type:"string"},}, required:["doc","comment"], additionalProperties:false,},execute:()=>{},render:({ stage, args, partialArgs, result, types })=>{const diff =generateDiff(editor.getJSON(), partialArgs.doc,{ hideTrailingRemovals: stage !=="executed",}); // Document is streaming in, update diff in the editorif(stage ==="receiving"){__showDiffInEditor__(diff); // Show the current diff in the chatreturn(<AiTooltitle="Modifying document…"><DiffPreviewdiff={diff}/></AiTool>);} // Document has fully streamed in, show confirm/cancel dialog in chatif(stage ==="executing"){__showDiffInEditor__(diff); return(<AiTooltitle="Modifying document…"> <AiTool.Confirmation types={types} confirm={async()=>{// On confirm, apply changes to the document, remove in-editor diff previewconst updatedDoc =applyDiff(editor.getJSON(), args.doc); editor.commands.setContent(updatedDoc);__showDiffInEditor__(null); return{ data:{ success:true}, description:"The user accepted the changes",};}} cancel={()=>{// On cancel, remove in-editor diff preview__showDiffInEditor__(null); return{ data:{ success:false}, description:"The user rejected the changes",};}} ><DiffPreviewdiff={diff}/></AiTool.Confirmation></AiTool>);} // stage === "executed"// Dialog has been clicked, show collapsed final diffreturn(<AiTooltitle={ result.data.success?"Document updated":"Update cancelled"}collapsed={true}><DiffPreviewdiff={diff}/></AiTool>);},})}/>);}
The editor now supports full-document understanding and structural manipulation
through AI, enabling copilot suggestions that can modify entire layouts while
keeping schema validity intact. Users can review changes inline, accept them
safely, and continue collaborating instantly as AI responses stream in real
time, creating a seamless, engaging authoring experience.
Embedding AI in structured, collaborative editors isn’t about prompt crafting,
it’s about architecture. Once you own your schema, diffing, and collaboration
layer, AI can operate natively within your product.
Whether you stream your own model output or use Liveblocks’ ready-made
AiChat component for
collaborative streaming, the principle is the same—responsiveness, control, and
trust.
At Flexum, we build structured, intelligent editing
experiences for modern SaaS products. The
Distribute copilot is one example of how
engineering precision can turn AI from a novelty into a first-class
collaborator.